2025-10-27 9:00
今回はURDFファイルのロボットをIsaacLabで使用できるようにし、強化学習を実行できるようにするまでの手順を説明します。
IsaacLabはNVIDIA社が提供するロボティクスプラットフォームで、強化学習やロボット制御の研究に利用されます。また、IsaacLabの学習や評価を行うためのシミュレータは同社のIsaacSimを使用します。
URDFファイルはROSなどで使用されるロボット定義記述フォーマット(XML)です。
IsaacLabではURDFをインポートするツールが用意されていて、URDFの資産をIsaacLabで強化学習に活用することができます。
動作確認環境
本記事の内容は以下の環境で動作確認を行っています。
なんと言ってもIsaacLabを動作させるにはNVIDIAのGPU(グラフィックボード)がなくては始まりません。
ハードウェア
・ GPU: NVIDIA GeForce RTX 4070(12GB)
・ CPU: Intel(R) Core(TM) i7-14700F
・ メモリ: 64GB
ソフトウェア
・ ホストOS: Ubuntu 22.04.5 LTS
・ Docker: 28.4.0
・ nvidia-container-toolkit: 1.17.8
・ NVIDIA Driver: 575.57.08
・ IsaacLab: 2.2.0
・ IsaacSim: 5.0.0
公式スペック表 と比べるとGPUはMinimumSpec未満のものでしたが、今回の内容においては十分軽快に動作していました。
準備編
IsaacLabを動作させるための環境構築手順を説明します。
本手順はUbuntu22.04上で作業することを想定しています。
IsaacLabの準備
IsaacLabはDockerイメージで提供されており、イメージにはIsaacSimも含まれていてすぐに動かすことができます。これら利点が大きいためDocker版を使用します。
注意
公式のDockerチュートリアル
の冒頭に「NVIDIAが提供するDockerイメージを使用する場合は
NVIDIAソフトウェアライセンス契約
に同意する必要があります」と記載があります。 必ず内容を確認し、同意した上で使用してください。
Docker本体のインストール
Docker本体のインストールがまだの方は、
公式ドキュメント
を参考にインストールしてください。
また、通常ユーザでDockerを使用するために
こちら
の
Manage Docker as a non-root user
の項目を行って下さい。
nvidia-container-toolkitのインストール
DockerコンテナがNVIDIA GPUを使用するために必要な、
nvidia-container-toolkit
を
公式
を参考にインストールします。
インストールサーバのaptへの追加
次のコマンドはターミナルへまとめてコピーして実行してください。
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
インストール
sudo apt update && sudo apt install -y nvidia-container-toolkit
Dockerイメージの取得
IsaacLabのDockerイメージをNVIDIAのコンテナレジストリから取得します。
docker pull nvcr.io/nvidia/isaac-lab:2.2.0
共有ディレクトリの作成
DockerコンテナとホストOS間でファイルを共有するためのディレクトリを作成します。
ディレクトリはこの後URDFファイルをコンテナと共有する為のものです。
mkdir ~/lab_share/
Dockerコンテナの起動
以下のコマンドでIsaacLabのDockerイメージからコンテナを起動します。長いコマンドですが、全てまとめてターミナルへコピペして実行してください。
-v ~/lab_share:/workspace/lab_share:rw
の部分が、先ほど作成した共有ディレクトリをコンテナ内の
/workspace/lab_share
にマウントする設定です。
xhost + docker run --name isaac-lab --entrypoint bash -it --gpus all -e "ACCEPT_EULA=Y" --rm --network=host \ -e "PRIVACY_CONSENT=Y" \ -e DISPLAY \ -v $HOME/.Xauthority:/root/.Xauthority \ -v ~/lab_share:/workspace/lab_share:rw \ -v ~/docker/isaac-sim/cache/kit:/isaac-sim/kit/cache:rw \ -v ~/docker/isaac-sim/cache/ov:/root/.cache/ov:rw \ -v ~/docker/isaac-sim/cache/pip:/root/.cache/pip:rw \ -v ~/docker/isaac-sim/cache/glcache:/root/.cache/nvidia/GLCache:rw \ -v ~/docker/isaac-sim/cache/computecache:/root/.nv/ComputeCache:rw \ -v ~/docker/isaac-sim/logs:/root/.nvidia-omniverse/logs:rw \ -v ~/docker/isaac-sim/data:/root/.local/share/ov/data:rw \ -v ~/docker/isaac-sim/documents:/root/Documents:rw \ nvcr.io/nvidia/isaac-lab:2.2.0
すると次のようなプロンプトが表示されます。これがDockerコンテナ内のターミナルです。
([]はホスト名に置き換わります)
root@[hostname]:/workspace/isaaclab#
ここで
/workspace/isaaclab
ディレクトリにはIsaacLab本体がインストールされています。lsコマンドで確認すると、以下のように様々なサンプルやドキュメントが入っていることがわかります。
root@[hostname]:/workspace/isaaclab# ls CITATION.cff LICENSE SECURITY.md apps environment.yml pyproject.toml tools CONTRIBUTING.md LICENSE-mimic VERSION docker isaaclab.bat scripts CONTRIBUTORS.md README.md _isaac_sim docs isaaclab.sh source
サンプルの起動確認
IsaacLabのサンプルを起動して動作するか確認します。
コンテナ内で次のコマンドを実行します。
python $ISAACLAB_PATH/scripts/reinforcement_learning/skrl/train.py --task=Isaac-Cartpole-v0
少しするとIsaacSimのウィンドウが立ち上がり、倒立振り子の強化学習シミュレーションが開始されます。
だんだん、倒立振り子が立つようになっていく様子がわかります。
シミュレーションを終了させる時は、コマンドを実行したターミナル上でCtrl+cを押してください。
ここまでで、IsaacLabの環境構築と動作確認が完了しました。
URDFファイルの準備
次に、IsaacLabで使用するURDFファイルを準備します。
URDFファイルのダウンロード
今回使用するURDFファイルは
こちら
に用意してあります。
ホストPC
上で次のコマンドを実行して、先ほど作成した共有ディレクトリにダウンロードします。
cd ~/lab_share git clone https://github.com/takahashi-e6/bike_scripts samples
ダウンロードしたディレクトリには次のファイルが入っています。
$ tree/ ├── bike.urdf → 自転車型ロボットのURDFファイル ├── copy_to_lab.sh → ファイルコピースクリプト ├── managed_bike_env_cfg.py → 強化学習の環境設定スクリプト ├── mdp/ → 強化学習の観測や報酬の定義スクリプトを格納 └── robots/ → ロボットモデル関連ファイルを格納
URDFファイルの確認
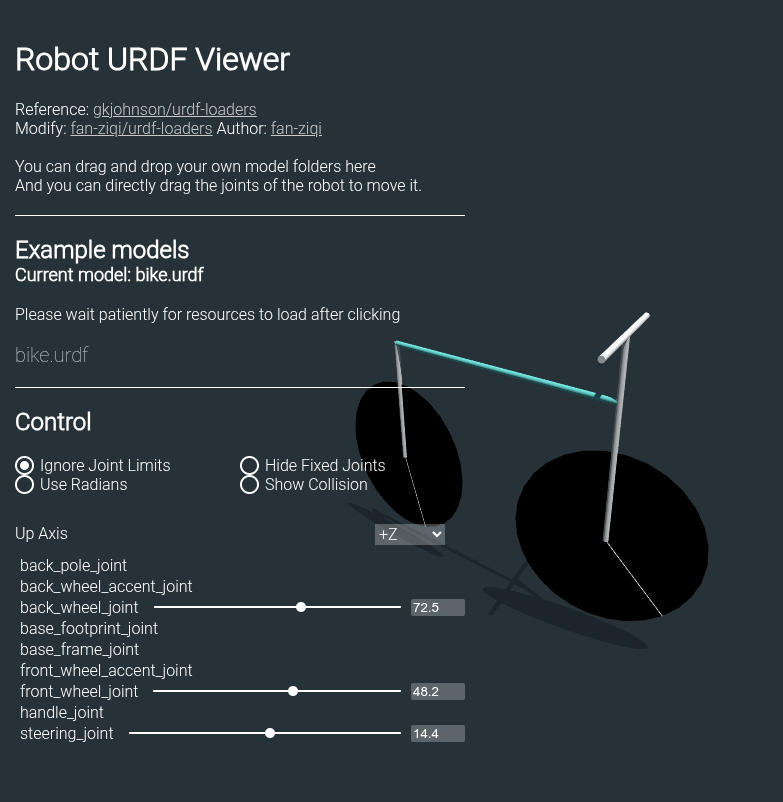
このURDFファイルはどんなロボットが定義されているのか確認しましょう。
ブラウザで
URDFビューア
を開き、
bike.urdf
をドラッグ&ドロップします。
すると、次のようにロボットの3Dモデルが表示されます。 自転車型のロボットで、2つの車輪と1つのハンドルを持っていることがわかります。
実践編
いよいよIsaacLabで強化学習を実行していきます。
まず、準備したURDFファイルをIsaacLabで使用できるUSDファイルに変換した後、強化学習実行の手順を説明します。
URDFファイルの変換
URDFファイルをUSDファイルに変換するために、コンテナ内で次のコマンドを実行します。
python $ISAACLAB_PATH/scripts/tools/convert_urdf.py /workspace/lab_share/samples/bike.urdf /workspace/lab_share/bike.usd --merge-joints --joint-stiffness 0.0 --joint-damping 0.0 --joint-target-type position
$ISAACLAB_PATH
はコンテナ内で自動的に設定されている環境変数で、IsaacLabのインストールディレクトリを指しています。 このコマンドを実行すると、
/workspace/lab_share/bike.usd
にUSDファイルが生成されます。
また、次の図のようなIsaacSimのウィンドウが立ち上がり、どのように変換されたがか確認できます。
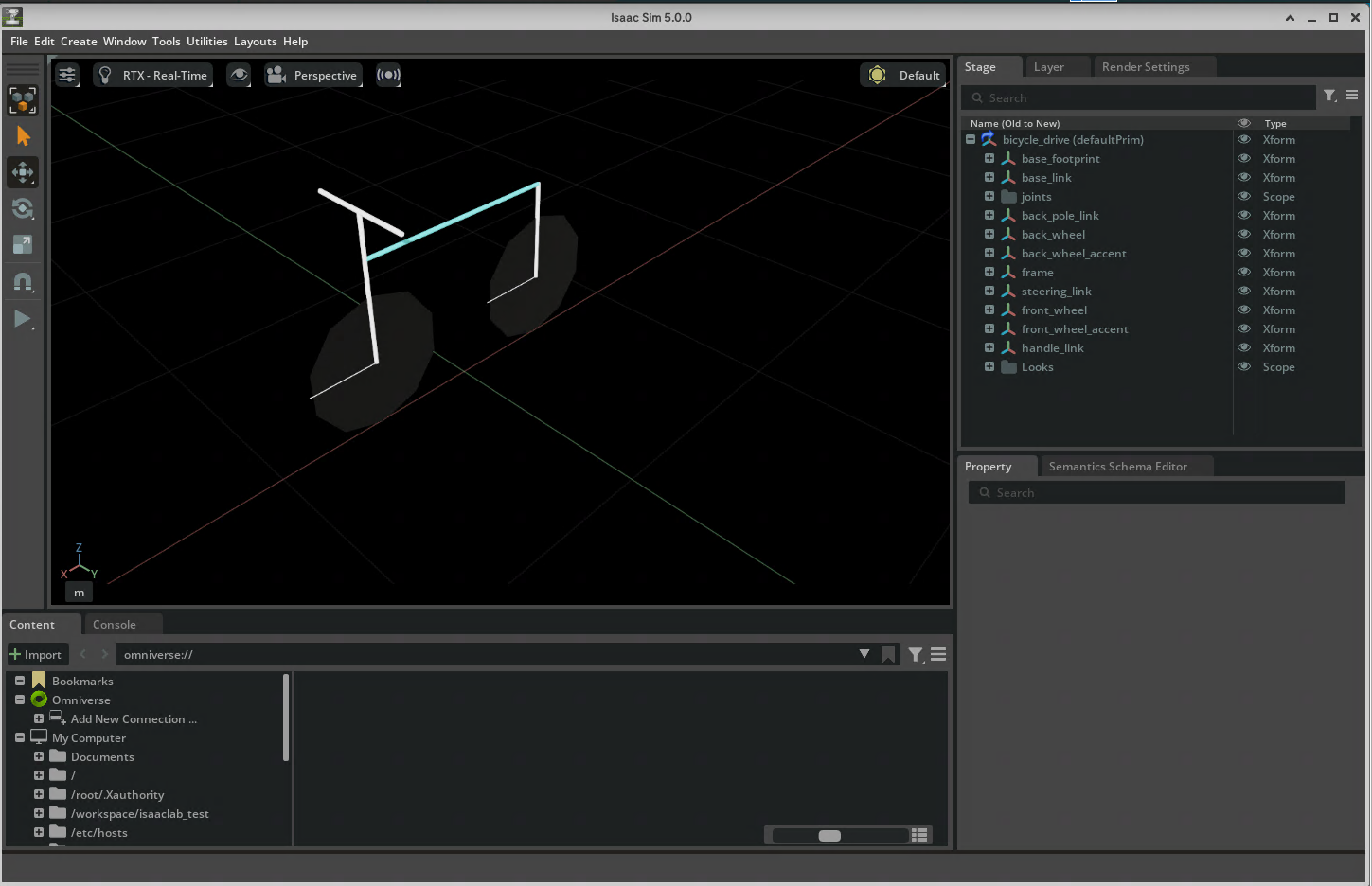
確認が済んだら、Xボタンをクリックしてウィンドウを閉じてください。
プロジェクトの作成
次に、IsaacLabのプロジェクトを作成します。
コンテナ内で次のコマンドを実行してください。
$ISAACLAB_PATH/isaaclab.sh --new
するとターミナル上でインタラクティブに初期設定を行うことができます。 設定は次のようにしてください。
? Task type: External ? Project path: /workspace/bike_project ? Project name: managed_bike ? Isaac Lab workflow: Manager-based | single-agent ? RL library: skrl ? RL algorithms for skrl: PPO
ラジオボタン の部分はスペースキーで選択、Enterキーで決定します。
もし、設定を間違えた場合は
/workspace/bike_project
ディレクトリを削除して、再度コマンドを実行してください。
パス設定
次に、作成したプロジェクトのpythonパスを通します。
cd /workspace/bike_project/managed_bike/ python -m pip install -e source/managed_bike
プロジェクトの構成
プロジェクトのディレクトリ構成と簡単な説明は次の通りです。
root@[hostname]:~# cd /workspace/bike_project/managed_bike/
root@[hostname]:/workspace/bike_project/managed_bike# tree
├── README.md → プロジェクトの説明と実行方法
├── logs → 学習したモデル保存先
├── outputs
├── scripts
│ ├── list_envs.py → 使用可能な環境一覧表示スクリプト
│ ├── random_agent.py
│ ├── skrl
│ │ ├── play.py → 学習済みモデルで実行するスクリプト
│ │ └── train.py → 強化学習を実行するスクリプト
│ └── zero_agent.py
└── source
└── managed_bike → タスク(学習の単位)のルートディレクトリ
・・・
├── managed_bike
│ ├── __init__.py
│ ├── tasks
│ │ ├── __init__.py
│ │ └── manager_based
│ │ ├── __init__.py
│ │ └── managed_bike
│ │ ├── __init__.py
│ │ ├── agents
│ │ │ ├── __init__.py
│ │ │ └── skrl_ppo_cfg.yaml → 学習アルゴリズムの設定ファイル
│ │ ├── managed_bike_env_cfg.py → タスクの設定スクリプト
│ │ └── mdp
│ │ ├── __init__.py
│ │ ├── rewards.py → 報酬の定義スクリプト
│ └── ui_extension_example.py
├── pyproject.toml
└── setup.py
強化学習スクリプトのコピー
用意した強化学習スクリプトを同梱のコピースクリプトを使って、プロジェクト内にコピーします。
cd ~/lab_share/samples ./copy_to_lab.sh
done
と表示されればコピー完了。
学習の実行
準備が整ったので強化学習を実行します。コンテナ内で次のコマンドを実行します。
python scripts/skrl/train.py --task=Template-Managed-Bike-v0 --num_envs=1000
学習が開始され、IsaacSimのウィンドウが立ち上がります。
ここで、
--num_envs=1000
は並列に実行する環境数を指定しています。もし、シミュレーションの動作が重そうであればこの数値を減らして様子を見て下さい。
この学習では「速度コマンドに追従しつつ、自転車が倒れずに走るようにする」ことを目標としています。
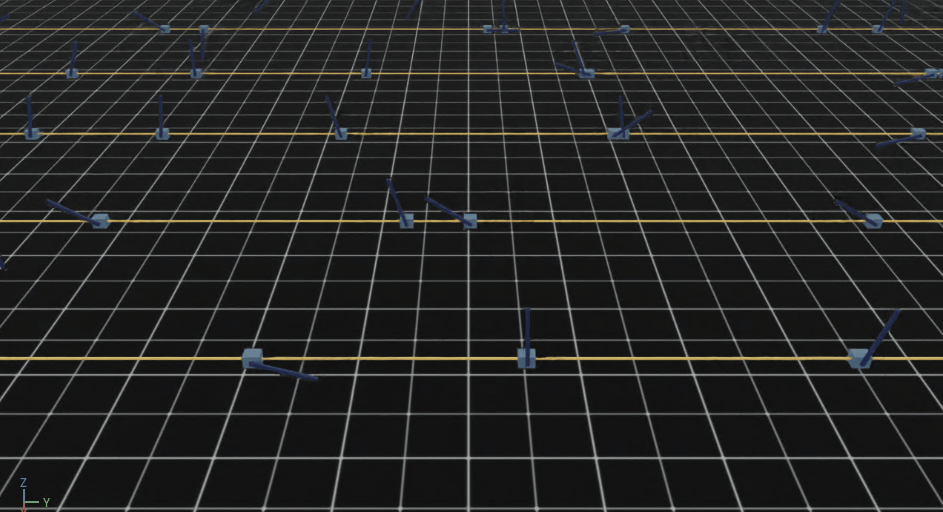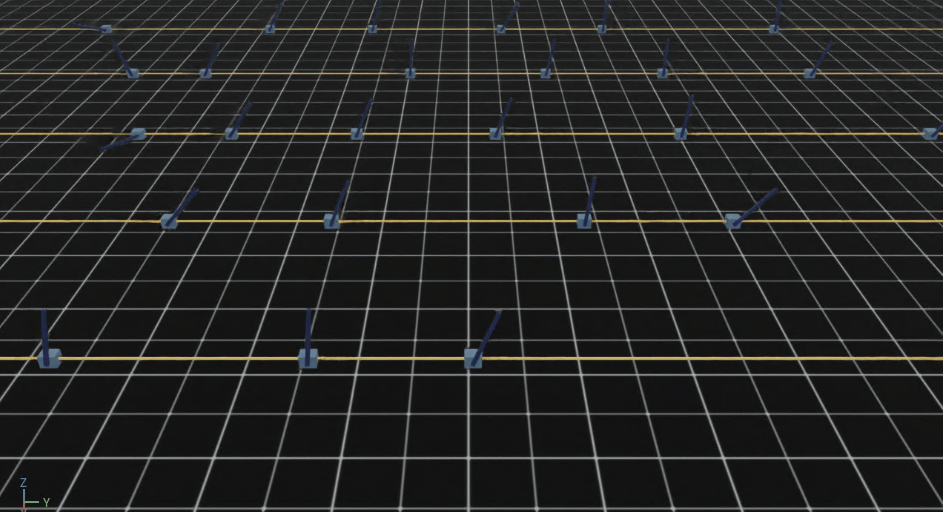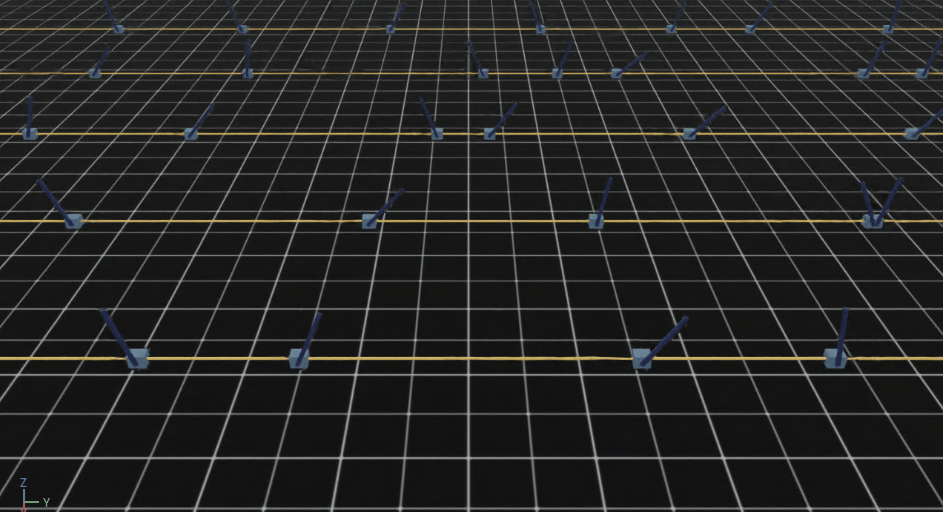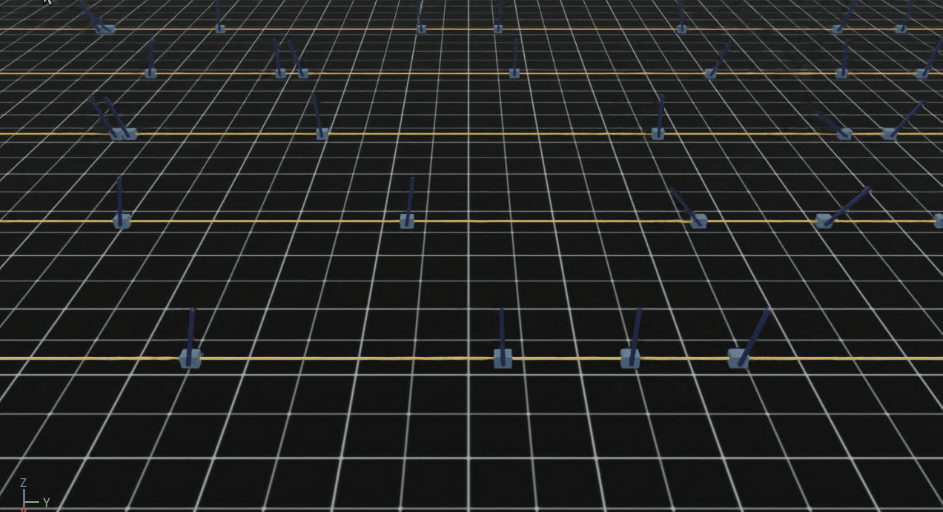
大量の自転車モデルが並ぶのは壮観です。
自転車の傍の矢印ですが
・ 緑が速度コマンドベクトル
・ 青が自転車の速度ベクトル
を表しています。
続けて見ていくと学習の進行に伴い、徐々に自転車が倒れずに走るようになっていく様子がわかります。

ターミナルを確認すると次のように学習の進行状況が表示されます。
13%|██████▉ | 641/4800 [00:34<03:19, 20.86it/s]
<
03:19の部分が学習完了までの予想時間です。
ちなみに本環境で今回の学習は3分程度かかりました。
学習済みモデルでの実行
学習が完了したので、学習済みモデルでシミュレーションを実行してみます。
まず、モデルの保存先ですが
/workspace/bike_project/managed_bike/logs/skrl/cartpole_direct/[時刻]_ppo_torch/checkpoints/best_agent.pt
になります。[時刻]の部分は各自の環境で読み直してください。
そして、次のコマンドの引数
--checkpoint
に保存先のパスを指定して実行します。
例えば次のようになります。
python scripts/skrl/play.py --task=Template-Managed-Bike-v0 --checkpoint=/workspace/bike_project/managed_bike/logs/skrl/cartpole_direct/2025-09-19_02-39-43_ppo_torch/checkpoints/best_agent.pt --num_envs=1
IsaacSimのウィンドウが立ち上がり、自転車が最初から走行している様子が見えます。
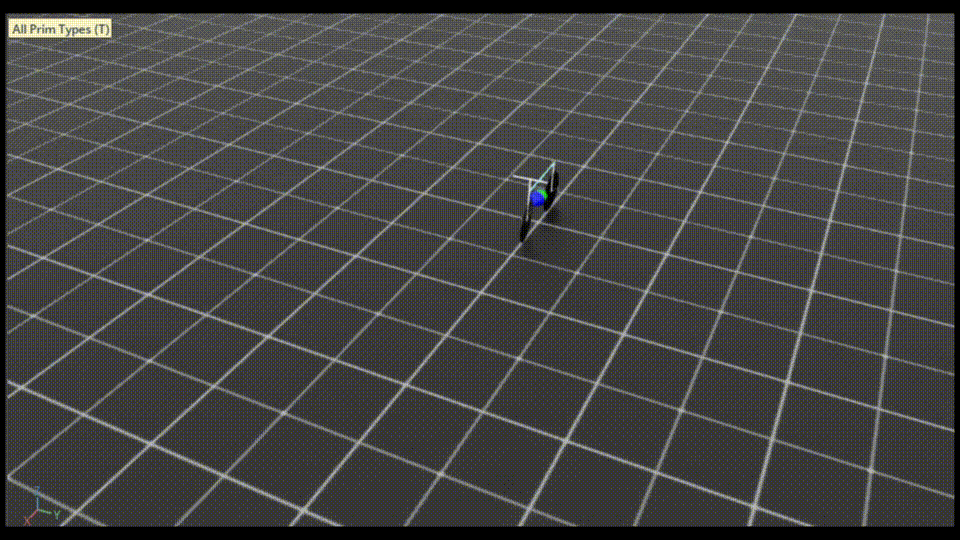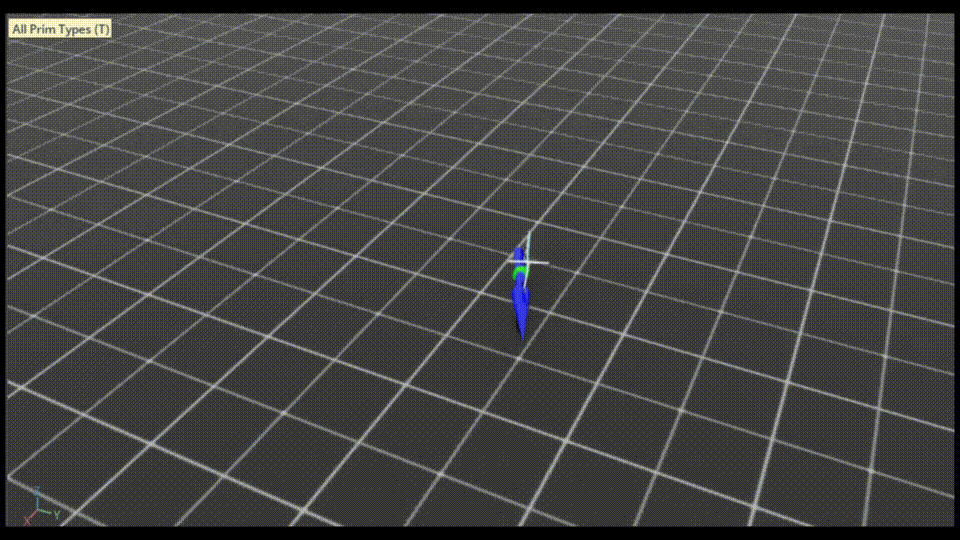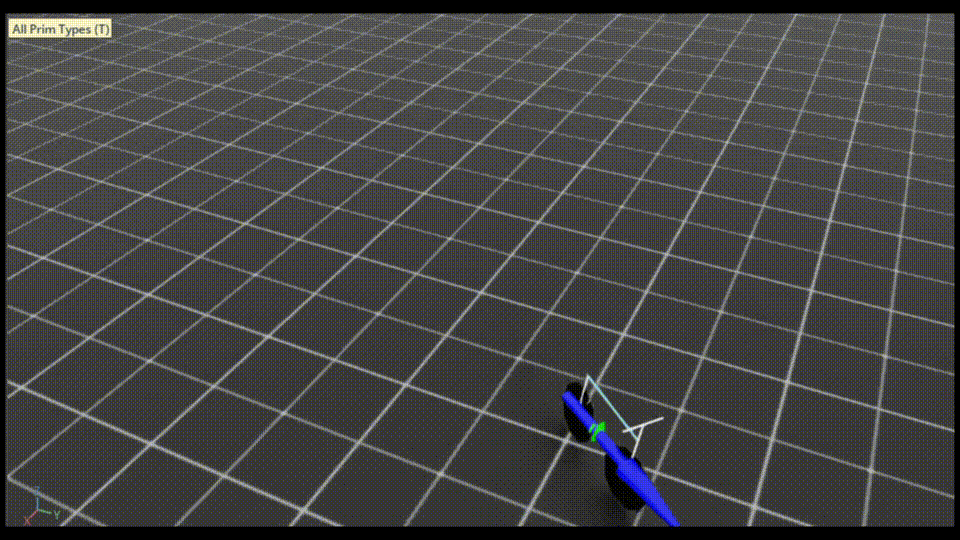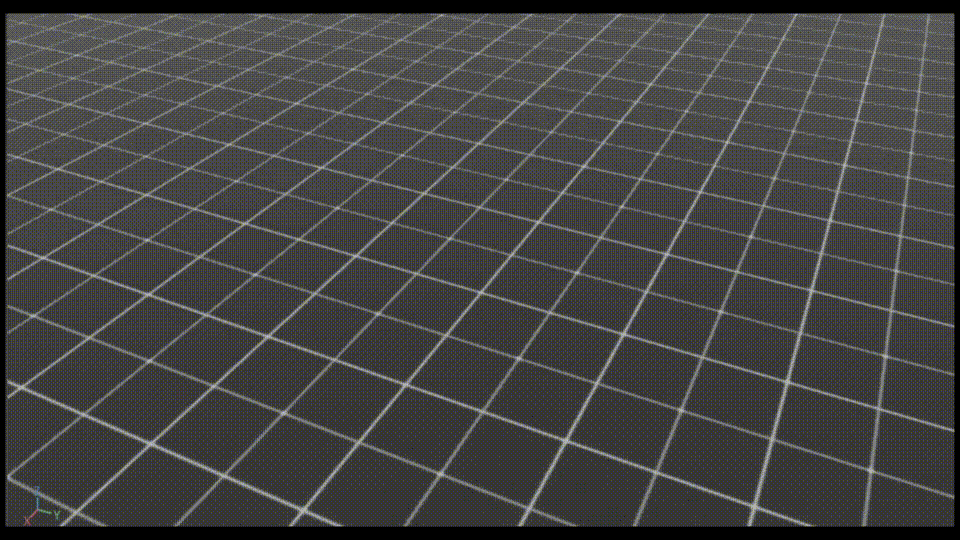
終了するときは、コマンドを実行したターミナル上でCtrl+cを押してください。
(簡単な)学習内容の説明
今回の学習内容を簡単に説明します。
改めて今回の目標は「速度コマンドに追従しつつ、自転車が倒れずに走るようにすること」です。
目標を達成する為に、次のような設定をpythonスクリプトで行っています。
・ コマンドの設定(CommandsCfg)
・ アクションの設定(ActionsCfg)
・ 観測の設定(ObservationsCfg)
・ イベントの設定(EventCfg)
・ 報酬の設定(RewardsCfg)
・ 終了の設定(TerminationsCfg)
ちなみに上記の設定は、
/workspace/bike_project/managed_bike/source/managed_bike/managed_bike/tasks/manager_based/managed_bike/managed_bike_env_cfg.py
で行っています。
コマンドの設定(CommandsCfg)
コマンドは、各エピソード/一定時間ごとにロボットへの指令で、ここでは一様分布のばらつきを持たせた速度ベクトル(lin_vel_x, lin_vel_y, ang_vel_z)が出力させます。
設定部分の抜粋は次の通りです。
@configclass
class CommandsCfg:
base_velocity = mdp.UniformVelocityCommandCfg(
asset_name="robot",
resampling_time_range=(5.0, 5.0),
rel_standing_envs=0.02,
rel_heading_envs=1.0,
heading_command=True,
heading_control_stiffness=1.0,
debug_vis=True,
ranges=mdp.UniformVelocityCommandCfg.Ranges(
lin_vel_x=(.0, 1.0), lin_vel_y=(-0.2, 0.2), ang_vel_z=(-math.pi/2, math.pi/2), heading=(-math.pi/4, math.pi/4)
),
)
mdp.UniformVelocityCommandCfg
クラスで行い、例えば
ranges
の部分で各軸のコマンドの範囲を指定しています。
アクションの設定(ActionsCfg)
アクション(制御入力)として、速度指令とハンドルへの位置指令が出力されるよう設定します。
設定部分の抜粋は次の通りです。
@configclass
class ActionsCfg:
back_wheel_vel = mdp.JointVelocityActionCfg(asset_name="robot", joint_names=["back_wheel_joint"], scale=2*math.pi)
steering_pos = mdp.JointPositionActionCfg(asset_name="robot", joint_names=["steering_joint"], scale=1.57)
速度指令へは
mdp.JointVelocityActionCfg
クラスを、位置指令へは
mdp.JointPositionActionCfg
クラスを使用しています。
また、引数の
joint_names
にはそれぞれ対応する軸の名前を、
scale
には出力値に乗じる倍率を指定します。
観測の設定(ObservationsCfg)
観測設定は自転車のロール軸の角速度
omg_r
、速度ベクトルと現在の速度ベクトルの一致度を示す値
alignment
、前進速度
forward_speed
を観測できるとします。
設定部分の抜粋は次の通りです。
@configclass
class ObservationsCfg:
@configclass
class PolicyCfg(ObsGroup):
omg_r = ObsTerm(func=mdp.roll_omg)
alignment = ObsTerm(func=mdp.alignment, params={"command_name": "base_velocity"})
forward_speed = ObsTerm(func=mdp.forward_speed)
def __post_init__(self) -> None:
self.enable_corruption = False
self.concatenate_terms = True
policy: PolicyCfg = PolicyCfg()
alignment
は
func=mdp.alignment
関数内で速度コマンドと現在の速度ベクトルの向きの一致度を計算しています。
より具体的に知りたい方は
/workspace/bike_project/managed_bike/source/managed_bike/managed_bike/tasks/manager_based/managed_bike/mdp/observations.py
を参照してみてください。
イベントの設定(EventCfg)
イベントにはシミュレーションの開始や環境のリセットをトリガとして、実行される処理を設定できます。
設定部分の抜粋は次の通りです。
@configclass
class EventCfg:
reset_base = EventTerm(
func=mdp.reset_root_state_uniform,
mode="reset",
params={
"pose_range": {"roll": (-0.2, 0.2)},
"velocity_range": {},
},
)
mode="reset"
は環境のリセットをトリガとすることを示し、
pose_range
でリセット時のロール姿勢の範囲を指定して、リセット時に自転車を少し傾けるようにしています。
報酬の設定(RewardsCfg)
報酬は次の5項目を設定しています。
・ 生存報酬: 自転車が倒れていないときに与えられる報酬
alive
・ 終了ペナルティ: 自転車が倒れたときに与えられるペナルティ
terminating
・ ロール角速度抑制報酬: ロール軸の角速度が小さいほど与えられる報酬
omg_r
・ 前進速度報酬: 前進速度が大きいほど与えられる報酬
forward_speed
・ 速度コマンドの向き一致報酬: 速度コマンドに対する向きの一致度が高いほど与えられる報酬
alignment
設定の抜粋は次の通りです。
@configclass
class RewardsCfg:
alive = RewTerm(func=mdp.is_alive, weight=1.0)
terminating = RewTerm(func=mdp.is_terminated, weight=-2.0)
omg_r_reward = RewTerm(
func=mdp.omg_reward,
weight=1.0,
)
forward = RewTerm(
func=mdp.forward_reward,
weight=2.0,
)
alignment = RewTerm(
func=mdp.alignment_reward,
weight=1.0,
params={"command_name": "base_velocity"}
)
RewTerm
は報酬項を定義するためのクラスで、関数
func
と重み
weight
を指定して報酬を計算します。 重みが負の場合はペナルティとして機能します。
より具体的に知りたい方は
/workspace/bike_project/managed_bike/source/managed_bike/managed_bike/tasks/manager_based/managed_bike/mdp/rewards.py
を参照してみてください。
終了の設定(TerminationsCfg)
終了条件は所定の時間に達したときと、自転車が倒れたときに終了するように設定しています。 終了条件を満たした環境は即リセットされ、次のシミュレーションが開始されます。
設定部分の抜粋は次の通りです。
@configclass
class TerminationsCfg:
time_out = DoneTerm(func=mdp.time_out, time_out=True)
fall_down = DoneTerm(
func=mdp.is_fallen,
params={"thresh_rad": 1.2,
"robot_cfg": SceneEntityCfg("robot")},
)
fall_down
は
func=mdp.is_fallen
関数内でロール角がしきい値を超えたかどうかを判定しています。
より具体的に知りたい方は
/workspace/bike_project/managed_bike/source/managed_bike/managed_bike/tasks/manager_based/managed_bike/mdp/terminations.py
を参照してみてください。
簡単ですが、以上が今回の学習内容の説明です。
まとめ
URDFファイルのロボットをIsaacLabで使用できるようにし、強化学習を実行するまでの手順を説明しました。 また、今回の強化学習内容についても簡単に説明しました。
ただし、今回行ったのはあくまで基本的な強化学習の手順であり、実機で動作させるためには次のような課題を詰めていく必要があります。
・ シミュレーションモデルの忠実度UP(タイヤ形状、実際のアクチュエータの性能による制限など)
・ センサーノイズの導入(各軸のエンコーダや傾き角を測るIMUなど)
・ ドメインランダム化(シミュレーションと実機の差を吸収するために、摩擦係数や質量などを変化させながらの学習)
・ より精度の高い学習(今回の学習済みモデルはまだまだ不安定。問題設定や報酬設定などを検討し改良する必要がある)
これら課題はありますが、高度な制御則を一から設計するより短時間でロボットを動作させることができるようになります。本記事で少しでも強化学習+シミュレーションの魅力が伝われば幸いです。